To
transfer a set of text files to a PDS as individual members, we need to create
a batch file. Let us transfer two text files to PDS USERID.DDF.TOOL. So, put the below two lines in a file and save the batch file with “srl” extension.
C:\Downloads\ASMEXIT.JCL
text~'USERID.DDF.TOOL(ASMEXIT)'
C:\Downloads\BUCKETS.JCL text~'USERID.DDF.TOOL(BUCKETS)'
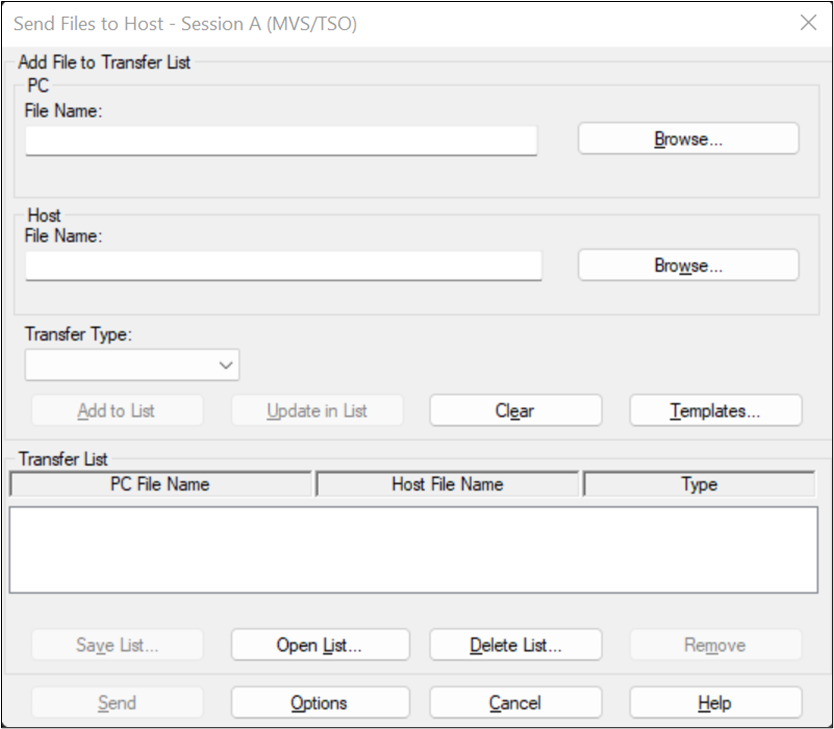
In the Mainframe IBM PCOM session, Select option “6 Command Enter TSO or Workstation commands” form ISPF main menu. From the IBM PCOM Menu, click on “Action” and then click on “Send File to Host”. You will get the below screen. In the below screen, click on “Options” and then you will get “File Transfer Settings” window.
In the “File Transfer Settings” window, click on “MVS/TSO” tab and select “text” under “Transfer type” drop down box. Then make sure “ascii” and “crlf” options are ticked in the “File options” and then select “Default” under “Record Format” drop down box.

Now go back to the “Send File to Host” window, click on “Open List” button and select the “srl” batch file that we already created and then click on “Send” button. This will transfer text files one by one to PDS as members.
C:\Downloads\BUCKETS.JCL text~'USERID.DDF.TOOL(BUCKETS)'
In the Mainframe IBM PCOM session, Select option “6 Command Enter TSO or Workstation commands” form ISPF main menu. From the IBM PCOM Menu, click on “Action” and then click on “Send File to Host”. You will get the below screen. In the below screen, click on “Options” and then you will get “File Transfer Settings” window.
In the “File Transfer Settings” window, click on “MVS/TSO” tab and select “text” under “Transfer type” drop down box. Then make sure “ascii” and “crlf” options are ticked in the “File options” and then select “Default” under “Record Format” drop down box.
Now go back to the “Send File to Host” window, click on “Open List” button and select the “srl” batch file that we already created and then click on “Send” button. This will transfer text files one by one to PDS as members.